
Warning
Problem: The current name of your GitHub Pages repository ("Solution: Please consider renaming the repository to "
http://".
However, if the current repository name is intended, you can ignore this message by removing "{% include widgets/debug_repo_name.html %}" in index.html.
Action required
Problem: The current root path of this site is "baseurl ("_config.yml.
Solution: Please set the
baseurl in _config.yml to "Education
-
 NJUSTDepartment of Computer Science
NJUSTDepartment of Computer Science
Ph.D. StudentSep. 2022 - present
Selected Publications (view all )
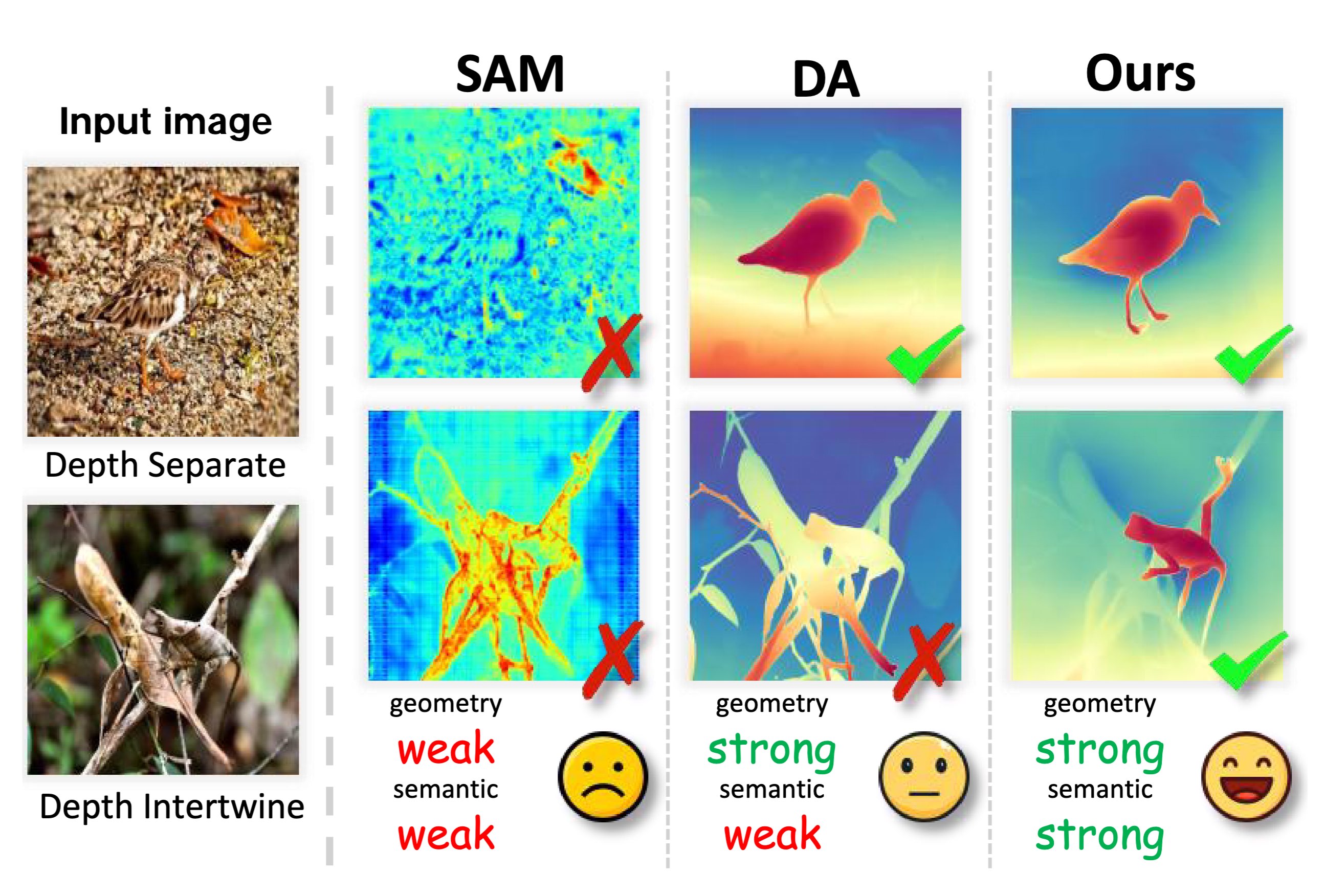
Beyond Appearance: Camouflaged Object Detection via Geometric Structure
jinyu Han, Changguang Wu, Fuming Sun, Jinhui Tang
CVPR 2026
We propose the Depth Segment Anything Model (DepthSAM), a MDE-adapted method for camouflaged object detection (COD).
Beyond Appearance: Camouflaged Object Detection via Geometric Structure
jinyu Han, Changguang Wu, Fuming Sun, Jinhui Tang
CVPR 2026
We propose the Depth Segment Anything Model (DepthSAM), a MDE-adapted method for camouflaged object detection (COD).
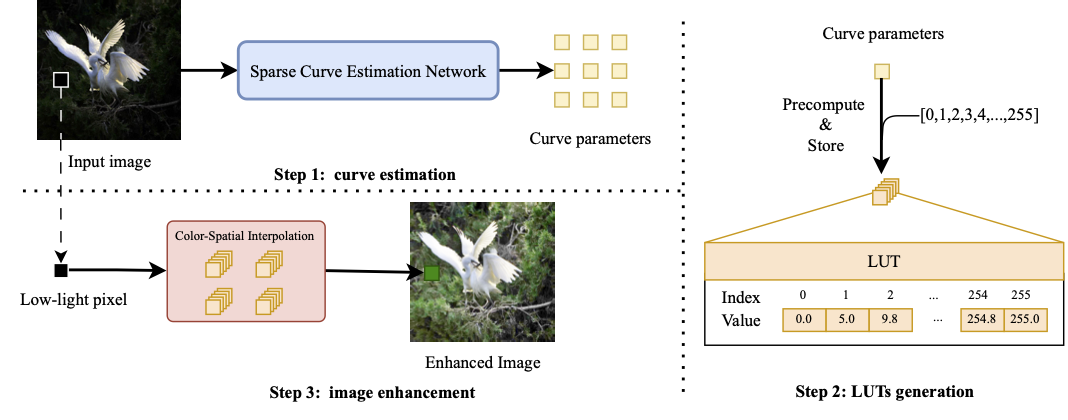
Sparse Curve Estimation for Real-Time Low-Light Ultra-High-Definition Image Enhancement
Changguang Wu, Jiangxin Dong, Hao Hou, Jinhui Tang
IEEE TCSVT 2026
We present an effective and efficient approach for low-light image enhancement, named Sparse Curve Estimation (SCE).
Sparse Curve Estimation for Real-Time Low-Light Ultra-High-Definition Image Enhancement
Changguang Wu, Jiangxin Dong, Hao Hou, Jinhui Tang
IEEE TCSVT 2026
We present an effective and efficient approach for low-light image enhancement, named Sparse Curve Estimation (SCE).
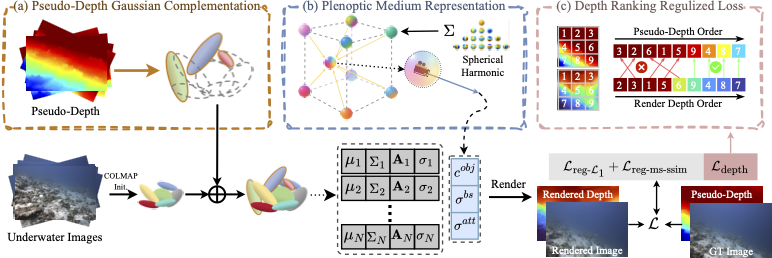
Plenodium: UnderWater 3D Scene Reconstruction with Plenoptic Medium Representation
Changguang Wu, Jiangxin Dong, Chengjian Li, Jinhui Tang
NeurIPS 2025
We present Plenodium (plenoptic medium), an effective and efficient 3D representation framework capable of jointly modeling both objects and participating media.
Plenodium: UnderWater 3D Scene Reconstruction with Plenoptic Medium Representation
Changguang Wu, Jiangxin Dong, Chengjian Li, Jinhui Tang
NeurIPS 2025
We present Plenodium (plenoptic medium), an effective and efficient 3D representation framework capable of jointly modeling both objects and participating media.
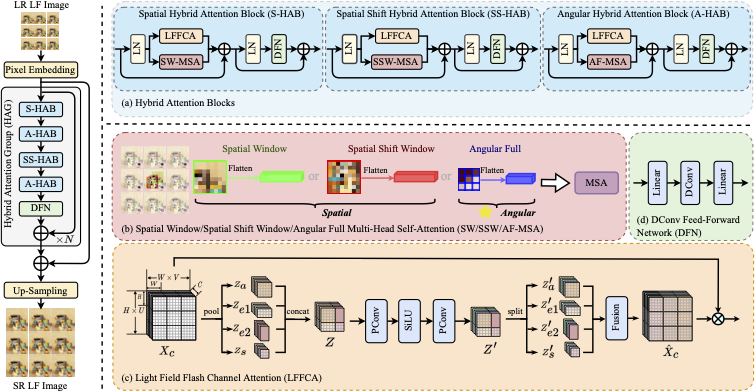
Light Field Super-Resolution with Hybrid Attention Network
Changguang Wu, Jiangxin Dong, Hao Hou, Jinhui Tang
Under review.
We propose a light field hybrid attention network for high-quality light field image super-resolution, which exploits not only the domain-specific information within the spatial/angular domain but also the spatial-angular correlation across domains.
Light Field Super-Resolution with Hybrid Attention Network
Changguang Wu, Jiangxin Dong, Hao Hou, Jinhui Tang
Under review.
We propose a light field hybrid attention network for high-quality light field image super-resolution, which exploits not only the domain-specific information within the spatial/angular domain but also the spatial-angular correlation across domains.
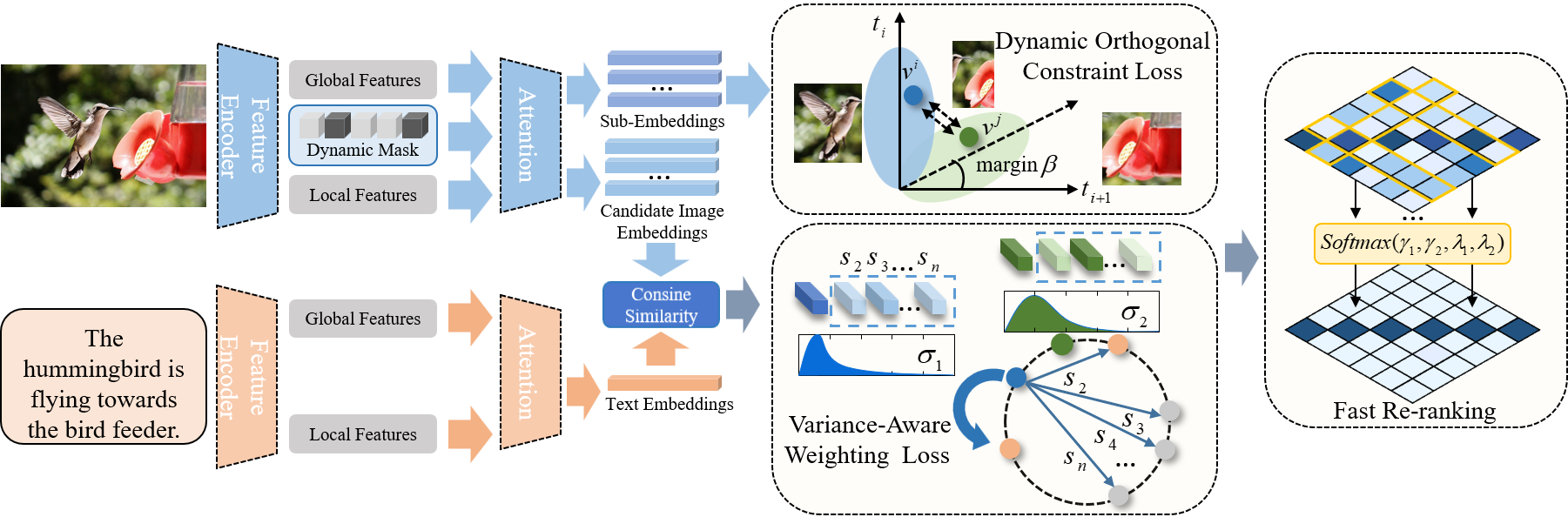
Dynamic Visual Semantic Sub-Embeddings and Fast Re-Ranking
Wenzhang Wei, Zhipeng Gui, Changguang Wu, Anqi Zhao, Dehua Peng, Huayi Wu
IEEE TMM 2024
In this work, we propose a Dynamic Visual Semantic Sub-Embeddings framework (DVSE) to reduce the information entropy.
Dynamic Visual Semantic Sub-Embeddings and Fast Re-Ranking
Wenzhang Wei, Zhipeng Gui, Changguang Wu, Anqi Zhao, Dehua Peng, Huayi Wu
IEEE TMM 2024
In this work, we propose a Dynamic Visual Semantic Sub-Embeddings framework (DVSE) to reduce the information entropy.